Reading
Font size
Line height
Reader theme
Explainers
Settings save to this browser only.
The Machine Manages Its Own Memory — and the Bug the Mocks Slept Through
Driving the Arena recall layer end-to-end on its own corpus: reindex → score → gate, dispatched through the control plane, recall@5 measured against 44 held-out questions. The first real drain caught a bug eight mock-injected unit tests had slept through — the case for operating the thing you built.
Series Second BrainTerms in this piece4
- Recall@kThe fraction of gold questions whose correct source is found in the top-k retrieved results. Chunk-recall@5 demands the exact (article, chunk) land in the top five; slug-recall@5 is the looser test that the right article appears. It is the single number that says whether retrieval is still doing its job.
- Control planeThe Arena cockpit's job layer: a queue, a dispatcher, and a sequential drain. Work is enqueued as a job, claimed one at a time (the Spark serves one model lane at a time), and executed through the shared MCP harness — so a re-index a human clicks and a re-index an agent triggers run the identical code path.
- Provenance cardA per-chunk trust record stamped at ingest — source, kind, doc_date, verdict, link — so retrieval can filter by where a passage came from. A Spark-measured number and an externally-claimed one are not interchangeable, and the provenance card is what lets the index tell them apart.
- Promotion gateThe rule that a re-index is only accepted if its recall@k is at least the prior index's, scored like-for-like on the same gold set and the same lane. The first run sets the baseline; every run after defends it. It turns "I rebuilt the index" into "I rebuilt the index and proved it didn't get worse."
A retrieval index is the easiest thing in an AI stack to let rot. You build it once, it works, and then the corpus grows, the embedder changes, a re-ingest silently drops a tenth of your documents — and nothing tells you. The one number that matters, does a question still find its answer, stays invisible until the day it fails you. This piece is about closing that gap on one DGX Spark: a recall layer that re-indexes itself, scores itself against a gold set, and refuses to promote a rebuild that makes retrieval worse — driven not by a script but through the same cockpit and the same dispatcher an agent uses. The sharper finding is what fell out the first time I drove the whole loop end-to-end on the blog’s own corpus: a bug that eight unit tests had never tripped, because every one of them mocked the part that was broken.
Why this matters for a solo builder on one machine
The thesis of this whole body of work is a continuously-updated world model — a system that writes artifacts and reads its own past back. The writing half is well-trodden here: notes become articles, articles become Book chapters. The reading half — querying your own corpus, and trusting the answer — is where most local setups quietly fail, because they treat the index as fire-and-forget. For a personal AI power user, the index is the memory. If it degrades without telling you, every downstream agent that retrieves from it degrades too, silently. Making recall a measured, gated, operator-visible number is the difference between a Second Brain you can lean on and one you merely hope is still good. And because it all runs on the machine under the desk — pgvector, a local embedder, the gold set — the documents and the queries never leave it.
Architectural context: the loop is the product
The recall layer — shipped as Orionfold Cortex — is a milestone of the Orionfold Arena cockpit, the fieldkit.memory module plus a knowledge pane — but the architecture that matters here is the loop, not the module. A rebuild is not done when it finishes; it is done when it has scored itself and proven it didn’t regress. Four stages chain through the control plane: re-index the corpus, score the fresh index against a held-out gold set, gate the result against the prior score, and serve provenance-filtered queries off the index that passed.
The reason the loop matters more than any one stage is that each stage is dispatched, not invoked. Clicking rebuild in the cockpit doesn’t run a shell script — it enqueues a reindex job and a chained rag_eval job onto the Arena control plane, which drains them one at a time through the same Model-Context-Protocol harness an agent uses to drive the box. The operator’s buttons and the agent’s tools are the same tools.
The journey: driving the loop on its own corpus
I brought the cockpit up and opened the knowledge pane against the blog’s live pgvector index — 49 published articles, already embedded. The pane was blunt about its own state.
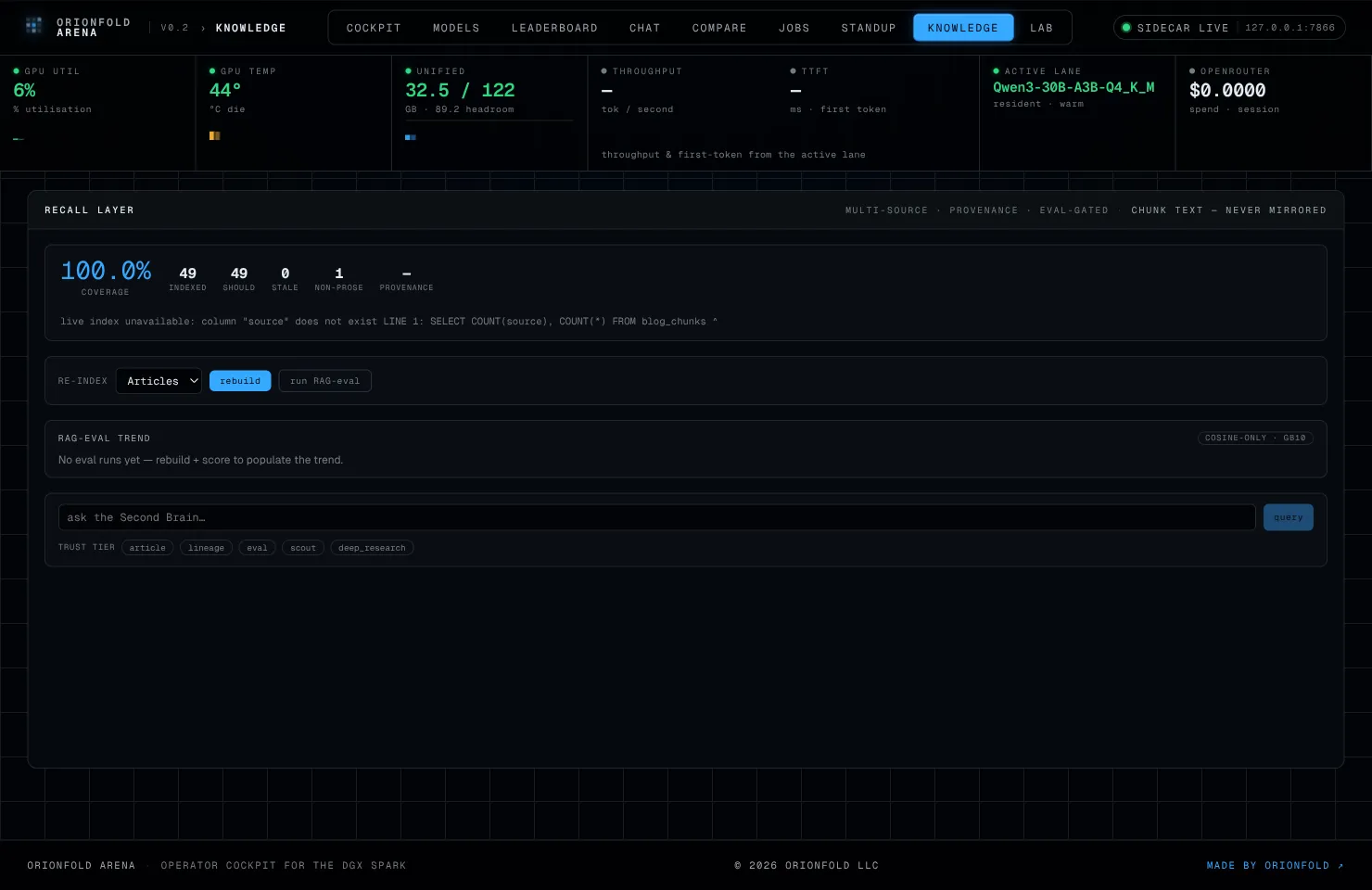
Coverage reads 100%, but the provenance figure is a dash and a red note runs underneath: live index unavailable: column "source" does not exist. The index had documents; it had no idea where any of them came from.
The provenance columns didn’t exist yet. That is the appliance’s design working as intended: the schema is additive and the first re-index installs it. So I clicked rebuild. Two jobs appeared on the control plane — the re-index, and the RAG-eval chained behind it to score whatever the rebuild produced.
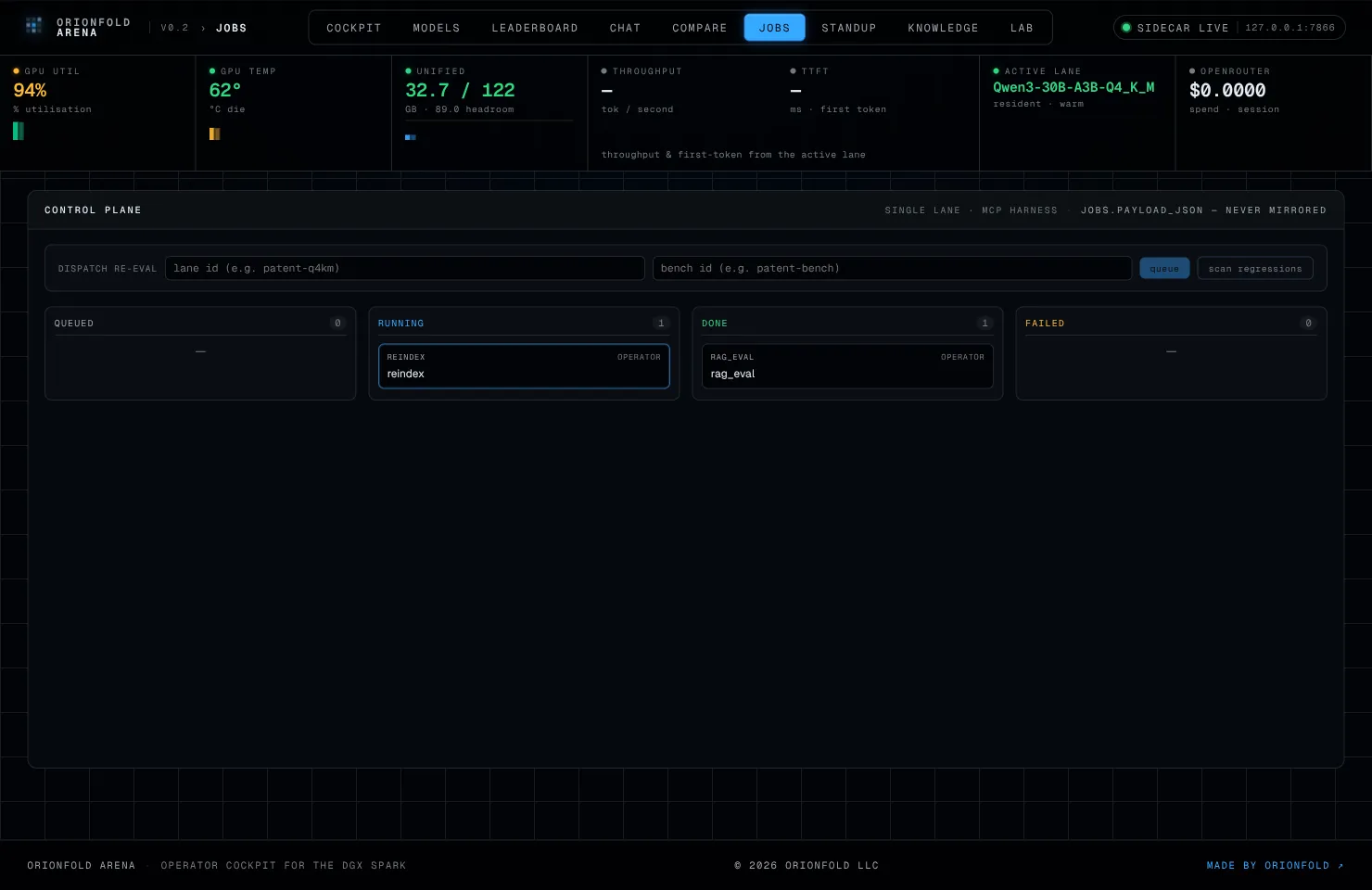
The board mid-drain. The re-index is running with the GPU pinned at 94% as it re-embeds every chunk; the scoring job sits beside it. Both are tagged OPERATOR — this is the human path, exercising the same dispatcher the agent uses.
And then the chained RAG-eval failed. Not the re-index — that ran clean, installed the provenance columns, and stamped all 313 chunks. The scoring job died, and the error was almost insulting in its smallness:
rag_eval failed error: name 'json' is not definedThe bug the mocks slept through
The scoring tool parses its gold set with json.loads. The module had shipped without a top-level import json — the single json. reference in the whole file, and no import to back it. One line. It had been broken since the recall layer landed, and nothing had caught it.
This is the whole argument of the piece in one defect. A mock is a promise that the thing it replaces behaves a certain way; it cannot verify that promise. The dispatcher tests proved the plumbing was sound — jobs enqueue, claim, persist, and surface their status correctly — and that was genuinely worth proving. But the tool at the end of the pipe had never been pulled through a real drain. The first time an operator clicked a button, the button found the bug in seconds.
The fix was the obvious one line, plus a regression test that does what the eight others didn’t — calls the real scoring function with a monkeypatched index and gold set, so the json.loads path actually executes without needing live infrastructure. Import added, test added, loop closed.
Verification: what a scored index looks like
With the fix in, I drove the loop again. This time the re-index ran clean, the chained RAG-eval ran clean, and the pane went from degraded to scored.
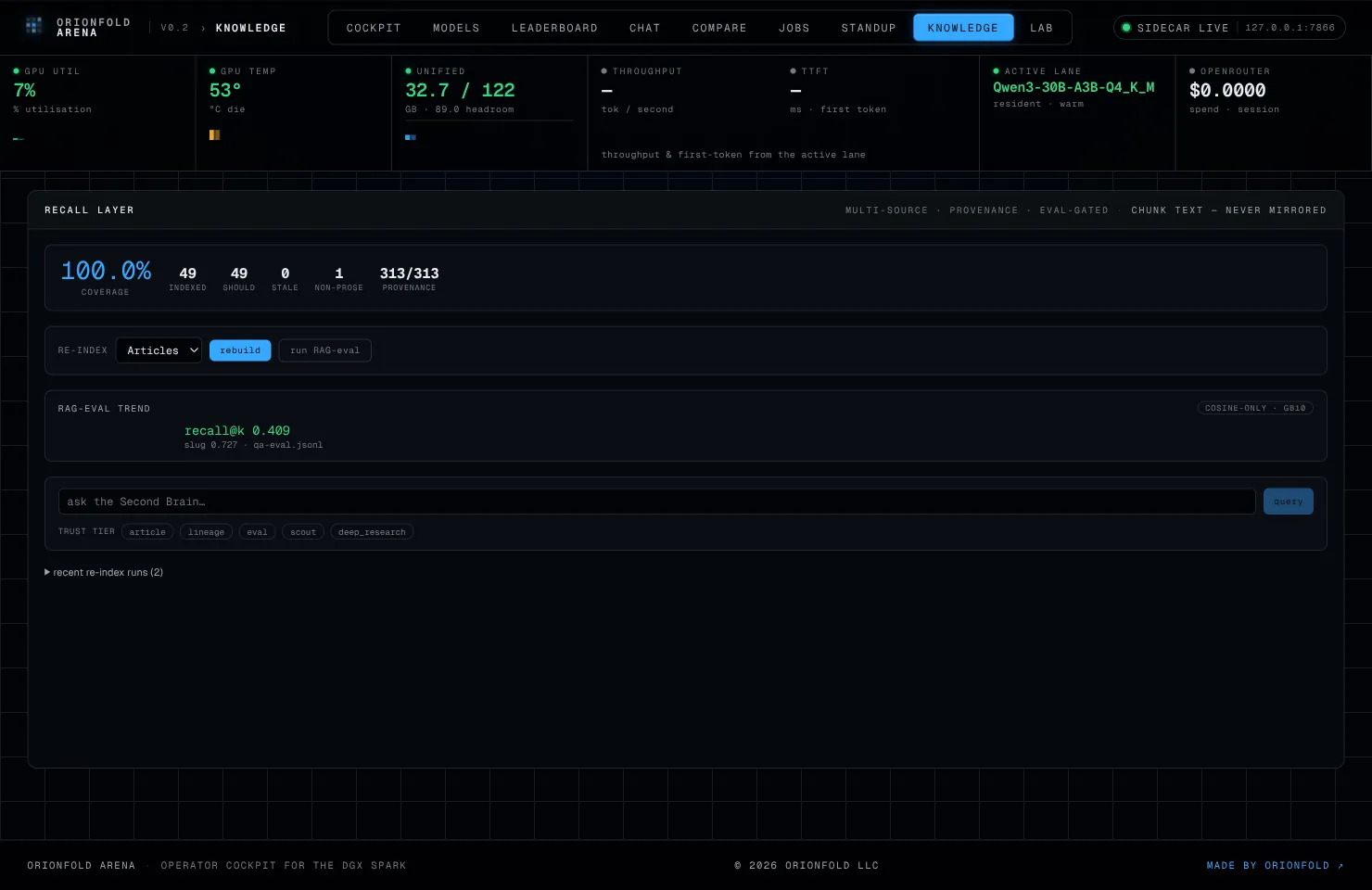
Provenance now reads 313/313 — every chunk stamped. The RAG-eval trend has its first point: chunk-recall@5 of 0.409, slug-recall@5 of 0.727, against the 44-question gold set, over an index of 49 articles and 313 chunks.
Those are the honest numbers on the cosine-only lane — no reranker in the path, because the GB10 has no reranker profile yet, and the tool raises rather than silently mislabel a reranked score as a cosine one. Slug-recall at 0.727 says the right article surfaces in the top five about three times in four; chunk-recall at 0.409 says the exact passage does about two times in five. For a single embedding model with no rerank stage and no query rewriting, that’s a believable floor and, more importantly, a tracked one.
Then the point of scoring: the gate. I ran a second RAG-eval against the now-stable index. The first score had no baseline, so it promoted unconditionally; the second compared against the prior 0.409, computed a delta of 0.0, and returned a promote verdict. The mechanism that matters is the one that wouldn’t promote — a rebuild that dropped recall would be flagged, not silently shipped.
Finally, the read surface — the reason the index exists. I asked the Second Brain, through the cockpit, how does GRPO use the eval harness as the reward model on the Spark?
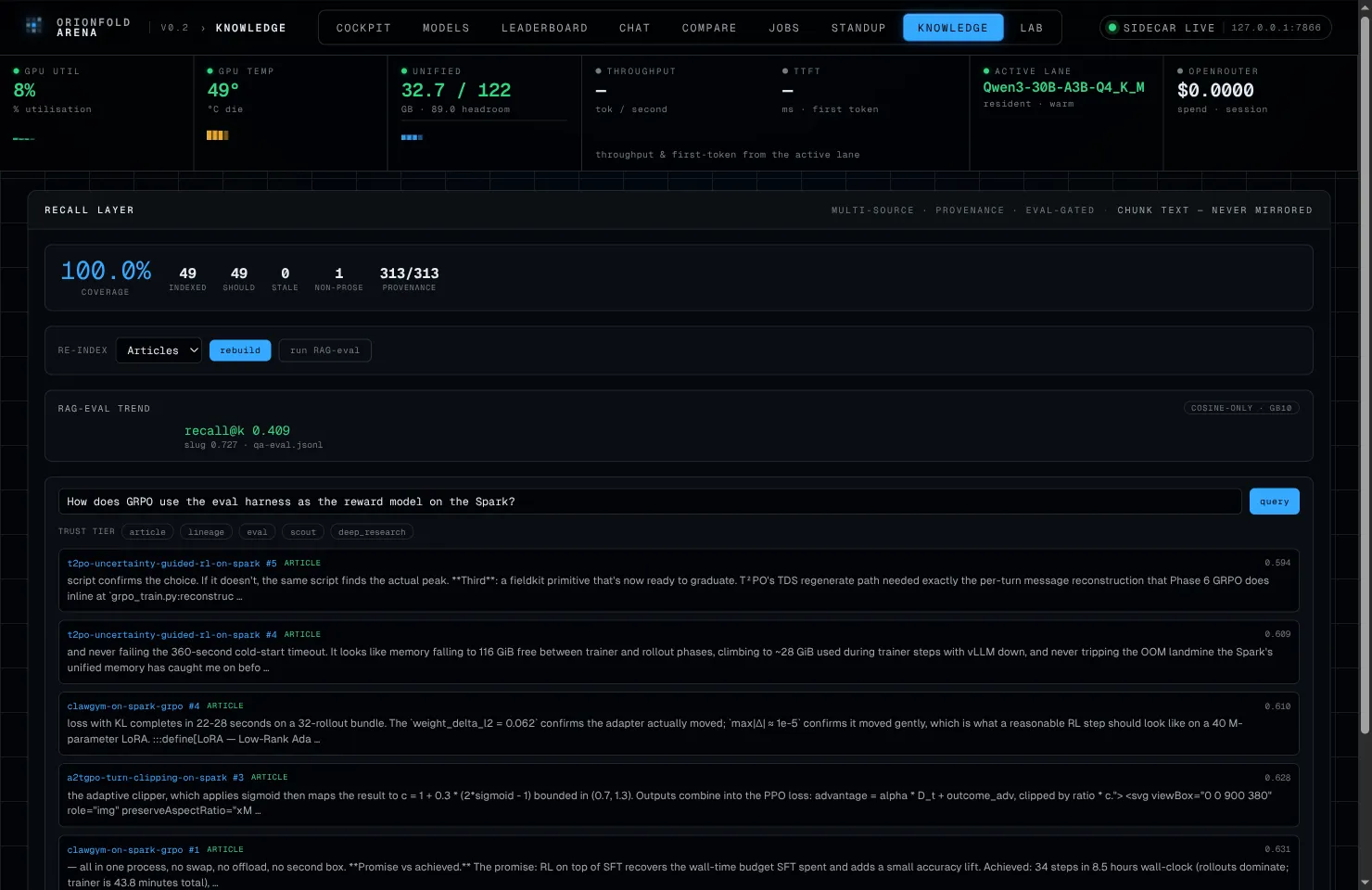
The query console returned cited chunks from exactly the right notes — the GRPO and trajectory-eval pieces — each tagged with its source and trust tier. The chips let you constrain retrieval to the provenance you trust for a given question.
The whole run closes on the morning standup — the control plane’s review surface, showing what ran and whether anything regressed.
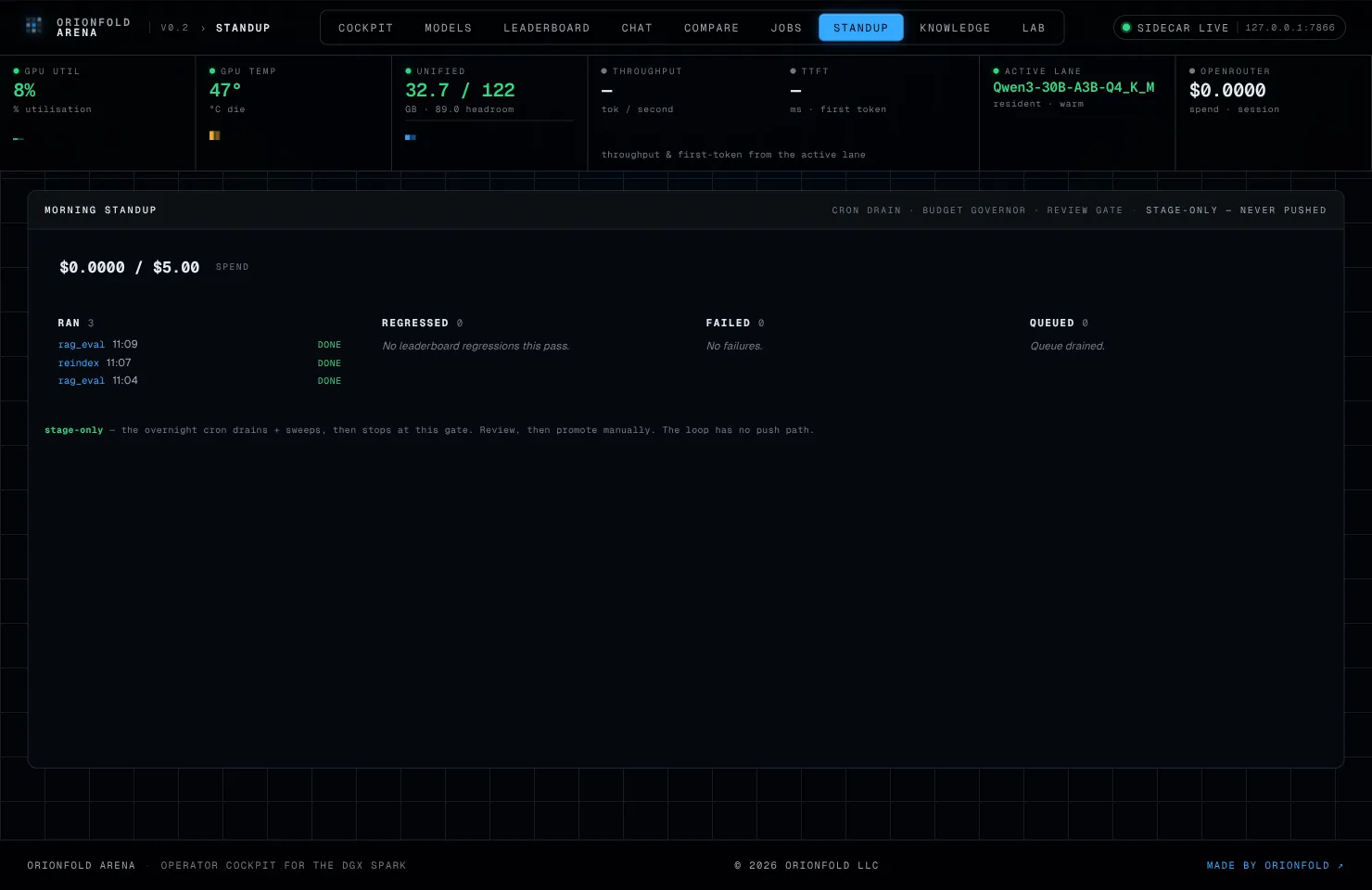
Three jobs ran — a re-index and two scoring runs — zero regressed, spend $0.00 (it all ran local), and the loop stops here: staged for review, never pushed. The autonomy is real; the auto-push is not.
Tradeoffs, gotchas, and what’s still bounded
The honest edges are worth naming. The recall@5 is a cosine-only baseline — no reranker, because there’s no GB10 reranker profile yet, so today’s number is a floor the rerank stage will lift, not a ceiling. The generator-side metrics — faithfulness, answer correctness — are null in this lane; they need a local generator NIM resident, and the Spark serves one model lane at a time. And the index is single-source today: the provenance schema spans five classes (article, lineage, eval, scout, deep-research), but only the article class is populated — the others are wired and empty. Folding experiment lineage into the same stamped index, so the Brain recalls not just what I wrote but what I measured, is the next real step.
The deeper gotcha is the one the bug taught: a green test suite is evidence about the contracts you wrote, not about the system. The dispatcher was well-tested and the tool it dispatched was broken, and both statements were true at once. The cheapest, highest-yield test I ran all session was clicking a button.
What this unlocks
Three things follow directly. First, a freshness hook: wire the re-index to fire on publish, and the index can never drift more than one article behind the corpus — the staleness that bites every fire-and-forget RAG becomes structurally impossible. Second, a gated nightly rebuild: let the control plane’s cron drain a re-index + score overnight, and read the recall delta in the morning standup — an index that defends its own recall while you sleep, and stages a review instead of pushing. Third, lineage-aware recall: ingest the experiment trials and eval runs into the same provenance-stamped index, and the Second Brain starts answering “what did I measure about this?” with cited, trust-tiered numbers — the read-back half of the world model the whole project is built toward.
Closing
The machine that builds machines has to be a machine that remembers — and a memory you can’t measure is a memory you can’t trust. Driving the recall loop end-to-end on its own corpus did two things a thousand green unit tests hadn’t: it put a real, gated recall number on the board, and it found the one line that had been broken since the layer shipped. The lesson generalizes past this one bug. Build the thing, then operate it — because the surface you operate is the only place the truth the suite slept through finally has to show itself. Next, the freshness hook: an index that re-scores itself the moment a new article lands, so the Second Brain is never more than one commit behind the mind it’s modeling.